AWS instances improve speed for machine learning
- November 11, 2020
- Steve Rogerson
Amazon Web Services has announced Amazon Elastic Compute Cloud (EC2) P4d instances, the latest version of its GPU-powered instances offering improvements in cost and speed for machine learning.
Now generally available, they are said to deliver three times faster performance, up to 60% lower cost and 2.5 times more GPU memory for machine-learning training and high-performance computing (HPC) workloads compared with the previous P3 instances.
P4d instances use eight Nvidia A100 Tensor Core GPUs and 400Gbit/s of network bandwidth, 16x more than P3 instances. Using P4d instances with AWS’s Elastic Fabric Adapter (EFA) and Nvidia GPU Direct RDMA (remote direct memory access), users can create P4d instances with EC2 UltraClusters capability.
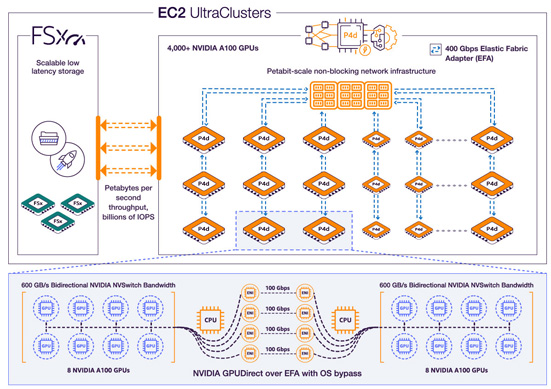
With EC2 UltraClusters, P4d instances can be scaled to more than 4000 A100 GPUs by making use of AWS-designed non-blocking petabit-scale networking infrastructure integrated with Amazon FSx for Lustre storage, offering on-demand access to supercomputing-class performance to accelerate machine-learning training and HPC.
Data scientists and engineers are continuing to push the boundaries of machine learning by creating larger and more-complex models that provide higher prediction accuracy for a broad range of use cases, including perception model training for autonomous vehicles, natural language processing, image classification, object detection and predictive analytics. Training these complex models against large volumes of data is a very compute, network and storage intensive task and often takes days or weeks.
Users not only want to cut down on the time to train their models, but also want to lower their overall spend on training. Collectively, long training times and high costs limit how frequently users can train their models, which translates into a slower pace of development and innovation for machine learning.
The increased performance of P4d instances speeds up the time to train machine-learning models by up to three times, reducing training time from days to hours, and the additional GPU memory helps train larger, more complex models.
As data become more abundant, users are training models with millions and sometimes billions of parameters, such as those used for natural language processing for document summarisation and question answering, object detection and classification for autonomous vehicles, image classification for large-scale content moderation, recommendation engines for ecommerce web sites, and ranking algorithms for intelligent search engines, all of which require increasing network throughput and GPU memory.
P4d instances have eight Nvidia A100 Tensor Core GPUs capable of up to 2.5 petaflops of mixed-precision performance and 320Gbyte of high bandwidth GPU memory in one EC2 instance. P4d instances are the first in the industry to offer 400Gbit/s network bandwidth with EFA and Nvidia GPU Direct RDMA network interfaces. This enables direct communication between GPUs across servers for lower latency and higher scaling efficiency, helping unblock scaling bottlenecks across multi-node distributed workloads.
Each P4d instance also has 96 Intel Xeon scalable (Cascade Lake) vCPUs, 1.1Tbyte of system memory, and 8Tbyte of local NVMe storage to reduce single node training times. By more than doubling the performance of P3 instances, P4d instances can lower the cost to train machine-learning models by up to 60%, providing more efficiency over expensive and inflexible on-premises systems.
HPC users can also benefit from P4d’s increased processing performance and GPU memory for demanding workloads such as seismic analysis, drug discovery, DNA sequencing, materials science, and financial and insurance risk modelling.
P4d instances are also built on the AWS Nitro System, hardware and software that has let AWS deliver an ever-broadening selection of EC2 instances and configurations, while offering performance that is indistinguishable from bare metal, providing fast storage and networking, and ensuring more secure multi-tenancy.
P4d instances offload networking functions to dedicated Nitro Cards that accelerate data transfer between multiple P4d instances. Nitro Cards also enable EFA and GPU Direct, which allows for direct cross-server communications between GPUs, facilitating lower latency and better scaling performance across EC2 UltraClusters of P4d instances. These Nitro-powered capabilities make it possible to launch P4d in EC2 UltraClusters with on-demand and scalable access to more than 4000 GPUs for supercomputer-class performance.
“The pace at which our customers have used AWS services to build, train and deploy machine learning applications has been extraordinary,” said Dave Brown, AWS vice president. “At the same time, we have heard from those customers that they want an even lower cost way to train their massive machine-learning models. Now, with EC2 UltraClusters of P4d instances powered by Nvidia’s latest A100 GPUs and petabit-scale networking, we’re making supercomputing-class performance available to virtually everyone, while reducing the time to train machine-learning models by three times, and lowering the cost to train by up to 60% compared to previous generation instances.”
Users can run containerised applications on P4d instances with AWS Deep Learning Containers with libraries for Amazon Elastic Kubernetes Service (EKS) or Elastic Container Service (ECS). For a more managed experience, P4d instances can be used via SageMaker, providing developers and data scientists with the ability to build, train and deploy machine-learning models quickly.
HPC users can leverage AWS Batch and ParallelCluster with P4d instances to help orchestrate jobs and clusters efficiently. P4d instances support all major machine-learning frameworks, including TensorFlow, PyTorch, and Apache MXNet, giving the flexibility to choose the framework that works best for the applications.
GE Healthcare is the $16.7bn healthcare business of GE. As a global medical technology and digital innovator, it helps clinicians make faster, more informed decisions through intelligent devices, data analytics, applications and services, supported by its Edison intelligence platform.
“At GE Healthcare, we provide clinicians with tools that help them aggregate data, apply AI and analytics to those data and uncover insights that improve patient outcomes, drive efficiency and eliminate errors,” said Karley Yoder, vice president at GE Healthcare. “Our medical imaging devices generate massive amounts of data that need to be processed by our data scientists. With previous GPU clusters, it would take days to train complex AI models, such as progressive GANs, for simulations and view the results. Using the new P4d instances reduced processing time from days to hours. We saw two- to three-times greater speed on training models with various image sizes, while achieving better performance with increased batch size and higher productivity with a faster model development cycle.”
Toyota Research Institute (TRI), founded in 2015, is working to develop automated driving, robotics and other human amplification technology for Toyota.
“At TRI, we’re working to build a future where everyone has the freedom to move,” said Mike Garrison, technical lead at TRI. “The previous generation P3 instances helped us reduce our time to train machine-learning models from days to hours and we are looking forward to utilising P4d instances, as the additional GPU memory and more efficient float formats will allow our machine-learning team to train with more complex models at an even faster speed.”



